Outsourcing Your Back Office Systems
Challenge:
Downtime of critical systems negatively impacts both the efficiency of your internal staff and the image presented to your customers. While the first step in minimizing downtime is of course to guarantee the quality and reliability of your hardware and software, a close second is fast diagnosis and response to unplanned problems. In even a moderate-sized IT environment, automated tools for performing monitoring of critical systems are a necessity. Word-of-mouth reporting of errors can lead to lengthy delays and difficult troubleshooting. Unfortunately, all too many off-the-shelf monitoring systems are inflexible, cumbersome to maintain, and worst of all produce an unacceptable number of false notifications, leading to a "boy who cried wolf" effect, and ultimately a loss in utility of the tool.
Solution:
The key components of a successful monitoring system are:
- Comprehensive Testing
Many monitoring systems have hooks for a large number of common services, but offer little in the way of custom extensibility for the less common but just as important services your company depends on. Such a 90% solution may satisfy the IT department whose only metric for success is that their webservers always return a certain word or phrase when connected to, but authenticated websites, non-HTTP services, or multi-page tests all vex such a simple system.
A flexible system allows you to define precise tests to mimic the complex behavior of a real user, then replay that and define varying metrics for success including response time, accuracy, and type of failure. - Dependency Handling
In any IT environment, there is some amount of dependent behavior: the website depends on the database server functioning correctly. The database server depends on the fileserver. And so on. While minimizing these dependent chains is a hallmark of good IT design, some amount of this is inevitable. When a failure occurs in, say, the database server, it is good to know at a moment's notice what services this affects. Monitoring of all services will tell you that, as each of the services will fail their tests and register as "down".
While knowing this is good, being notified of each and every unavailable service instead of merely the root cause wastes time and slows the troubleshooting process. Most high-availability environments use something like an automated paging system to notify systems administrators when a server or application is malfunctioning. Without dependency tracking, a service with 10 other services depending on it would generate 11 separate pages: one for the actual failure, and 10 reflections of that failure in the dependent services. With proper dependency tracking, notifications are only generated for the root problem, allowing them to be dealt with as quickly as possible.
- Minimal False Positives
An inevitable side effect of any automated monitoring system is "false positives", or notifications of a nonexistent problem. Providing world-class responsiveness to problems requires a fine balancing act between quick response times and avoiding false positives.
For example, a reasonable configuration might require that a remote webserver timeout an attempted connection three times, tried once per minute before a notification is actually sent. Assuming the test is in general performed once every five minutes, that makes the worst case downtime before a notification is sent eight minutes (5 + 3). While in theory a notification could be sent out on the first failure, sporadic temporary slowness in internet response times would lead to a constant barrage of false positives, leading to a loss of confidence in the tools by the support staff. ("What's that? Oh, it's just that server again; it's probably just net; I'll check it later.")
A good monitoring setup allows for precise tuning of timeouts, intervals of testing, and responses. For example, if response times are merely slow, that could be considered merely a "warning" state, which would result in notification of the 1st level response team. A "critical" state (perhaps an actual server error message response) could notify a 2nd level response team.
- Reporting
Responding to unplanned downtime is the first and most important use of any automated monitoring system. Keeping a record of the cause and effect of systems malfunctions, however, is not only an excellent aid for future problem prevention efforts but also invaluable for providing your customers with confirmed uptime numbers. If the logging system is integrated with the monitoring, allowances can be made for planned downtimes, to avoid polluting unplanned downtime statistics with planned downtime numbers.
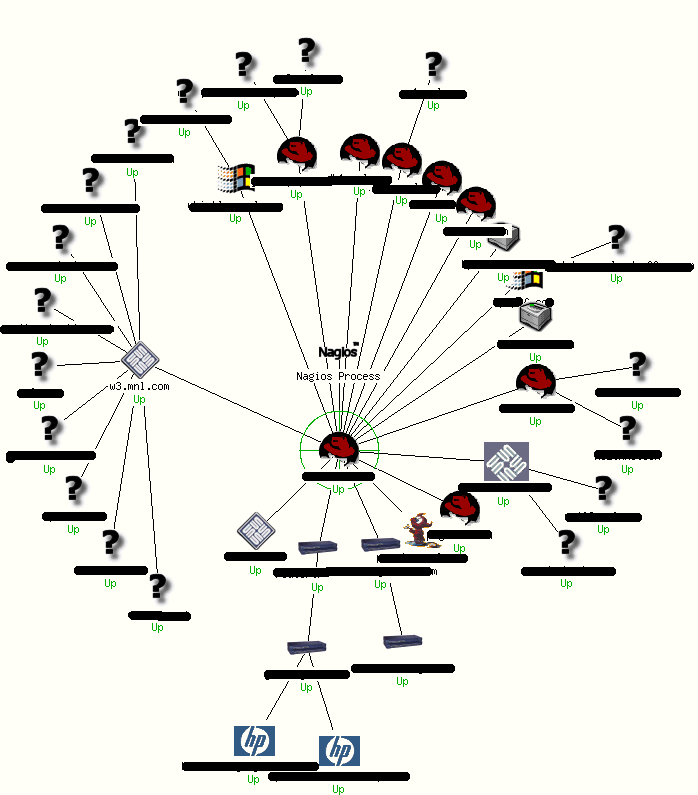 RESULT:
RESULT:
Monitoring in Practice
Media Net Link has a diverse IT environment with multiple fileservers, webservers, and mailservers, and for LAN access servers for virtual every protocol in the book (NFS, NIS, SMB, DNS, DHCP, SMTP...) To handle this heterogeneous blend of services and unify the monitoring process, we moved from a commercial offering, SiteScope to the freely available Open Source Nagios.
Within Nagios, we have put some type of active or passive monitor in place for virtually every service provided both to our external customers and our local employees. We monitor 93 services across 40 virtual and physical hosts. Examples of services include:
- Web services: HTTP and HTTPS (including authentication)
- Simple host "up": PING
- CPU load
- Disk space
- SSH access
- Print services: LPD, HPJD
- Mail services: POP3, IMAP, SMTP
- DNS
- Raid array failure status
- Remote Windows access
Along with monitoring, within the same framework we have incorporated a measure of "self-healing" to some of the services. While the ideal IT solution is to repair or replace services that repeatedly fail in predictable ways, some services are irreplaceable or unfixable, due to availability or for business reasons. In these cases, response time to the problem can be improved by building "healing" into the monitoring system itself. For instance, a recent release of popular "spam blocking" software would periodically stop functioning properly. Though we engineered the mailsystem to work around such a failure, it still meant that incoming mail was not being properly processed. Unfortunately, the error state was not trivial to detect: the software continued to function apparently normally, the only sign of a problem was that mail was passed through untreated. Therefore, using the flexible extensibility of Nagios, we built a monitor which performed a "deep test" of the functionality of the spam blocker, and if it failed to work, tried to repair the problem by restarting the blocking software. If this failed, then it generated a notification. This event was logged, but it was fixed without the need for systems administrator intervention (particularly appreciated at 2:30am.)
In summary, Media Net Link can design and implement a flexible, thorough, and low-maintenance monitoring system that provides the best possible response times for unplanned problems, and helps your company plan and track for an even more successful future.
- Case Studies (Top Four)
- MNL Builds sophisticated Reference Management System for EMC2
EMC2 - Partner/Reseller Sales Marketing Portal
Cisco Systems - Dynamic Online Catalog
Tyco Electronics
- Athena for Sarbanes-Oxley
MAP Communications